Я замахнулся на эту тему здесь. Но решил вынести в отдельную ветку, поскольку она слишком велика и не связана напрямую с отказоустойчивостью или распределением нагрузки на двух провайдеров.
Для начала - вот такая замечательная новость:
QoS Packet Flow in RouterOS v6
v6 CHANGES
improved overall router performance when simple queues are used
improved queue management (/queue simple and /queue tree) - easily handles tens of thousands of queues;
/queue tree entries with parent=global are performed separately from /queue simple and before /queue simple;
new default queue types: pcq-download-default and pcq-upload-default;
simple queues have separate priority setting for download/upload/total;
global-in, global-out, global-total parent in /queue tree is replaced with global that is equivalent to global-total in v5;
simple queues happen in different place - at the very end of postrouting and local-in chains;
simple queues target-addresses and interface parameters are joined into one target parameter, now supports multiple interfaces match for one queue;
simple queues dst-address parameter is changed to dst and now supports destination interface matching;
Т.е. все руководства, посвящённые Queue Tree требуют изменения и поправок.
Качество обслуживание и дерево очередей
Правила форума
Как правильно оформить вопрос.
Прежде чем начать настройку роутера, представьте, как это работает. Попробуйте почитать статьи об устройстве интернет-сетей. Убедитесь, что всё, что Вы задумали выполнимо вообще и на данном оборудовании в частности.
Не нужно изначально строить Наполеоновских планов. Попробуйте настроить простейшую конфигурацию, а усложнения добавлять в случае успеха постепенно.
Пожалуйста, не игнорируйте правила русского языка. Отсутствие знаков препинания и неграмотность автора топика для многих гуру достаточный повод проигнорировать топик вообще.
1. Назовите технологию подключения (динамический DHCP, L2TP, PPTP или что-то иное)
2. Изучите темку "Действия до настройки роутера".
viewtopic.php?f=15&t=2083
3. Настройте согласно выбранного Вами мануала
4. Дочитайте мануал до конца и без пропусков, в 70% случаев люди просто не до конца читают статью и пропускают важные моменты.
5. Если не получается, в Winbox открываем терминал и вбиваем там /export hide-sensitive. Результат в топик под кат, интимные подробности типа личных IP изменить на другие, пароль забить звездочками.
6. Нарисуйте Вашу сеть, рисунок (схему) сюда. На словах может быть одно, в действительности другое.
Как правильно оформить вопрос.
Прежде чем начать настройку роутера, представьте, как это работает. Попробуйте почитать статьи об устройстве интернет-сетей. Убедитесь, что всё, что Вы задумали выполнимо вообще и на данном оборудовании в частности.
Не нужно изначально строить Наполеоновских планов. Попробуйте настроить простейшую конфигурацию, а усложнения добавлять в случае успеха постепенно.
Пожалуйста, не игнорируйте правила русского языка. Отсутствие знаков препинания и неграмотность автора топика для многих гуру достаточный повод проигнорировать топик вообще.
1. Назовите технологию подключения (динамический DHCP, L2TP, PPTP или что-то иное)
2. Изучите темку "Действия до настройки роутера".
viewtopic.php?f=15&t=2083
3. Настройте согласно выбранного Вами мануала
4. Дочитайте мануал до конца и без пропусков, в 70% случаев люди просто не до конца читают статью и пропускают важные моменты.
5. Если не получается, в Winbox открываем терминал и вбиваем там /export hide-sensitive. Результат в топик под кат, интимные подробности типа личных IP изменить на другие, пароль забить звездочками.
6. Нарисуйте Вашу сеть, рисунок (схему) сюда. На словах может быть одно, в действительности другое.
-
Barvinok
- Сообщения: 104
- Зарегистрирован: 28 фев 2012, 23:21
-
Barvinok
- Сообщения: 104
- Зарегистрирован: 28 фев 2012, 23:21
Прежде чем браться за дерево очередей, я полагаю лучшим начать с простого и разобрать такую хитрую очередь, как PCQ.
Источники:
Руководства:Очереди - PCQ
Руководства:Очереди - Взрывной режим прохождения трафика (Burst)
Queues - PCQ Examples
Начну с того, что PCQ - не совсем очередь. Это скорее некое устройство, состоящее из PCC, FIFO (собственно, очереди) и Token Bucket (ограничителя потока).
Судите сами:
Т.е. сначала мы при помощи pcq-classifier разделяем поток на струи по признаку адреса/порта отправителя или получателя. Подобно PCC!
Затем полученные струи выстраиваются в обычную очередь FIFO (используются такие настройки, как pcq-limit и pcq-total-limit).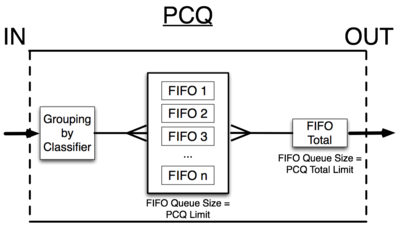
При этом к ним применяются ограничения, ровно такие же, как в HTB (pcq-rate вместо limit-at) и даже возможны всплески (ключи burst-limit, burst-time, burst-threshold)!
Очевидно, что это могучий инструмент. И если его грамотно использовать, то можно решить многие из повседневно встречающихся задач, не прибегая к дереву очередей.
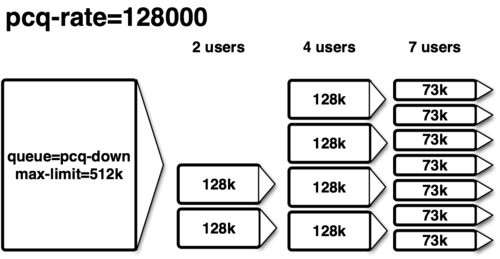
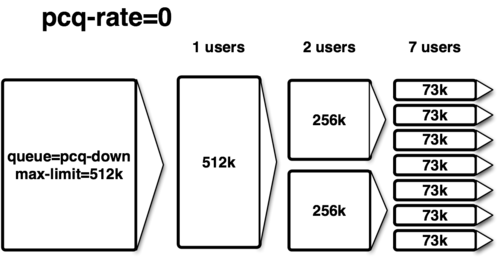
Моя задача проста: поровну распределить трафик между пользователями локальной сети (точно как в PCQ Examples).
Насколько я знаю, единственный способ направить поток пакетов в очередь - это выделить его в таблице Mangle любой цепочки. Что-бы снизить нагрузку на маршрутизатор, я сначала выделю соединения, а затем уже на основе этих меток выделю пакеты:
Затем я чуть подправил очереди, заботливо созданные разработчиками RouterOS:
В полном виде они теперь выглядят так:
Ну и третьим шагом я создаю простую очередь:
С помощью target вы указываете направление, относительно которого будет считаться исходящий и входящий трафик!
В данном случае я взял за основу направление в локальную сеть: оно считается входящим (download).
И ещё раз хочу обратить внимание вот на что.
Даже в этом простом примере у нас есть вложенность ограничений и всплесков. Мы можем настроить ограничения для потоков PCQ (pcq-rate) и для всей очереди (limit-at, max-limit).
То же самое касается "вёдер", в которых накапливаются марки для всплесков: pcq-burst-rate, pcq-burst-threshold, pcq-burst-time для PCQ и burst-limit, burst-threshold, burst-time для очереди в целом.
Представляете, какую невероятную гибкость это нам даёт?
К примеру, мы можем на первом шаге выделить трафик по виду (HTTP, ICMP, P2P) и отправить в разные очереди с разными ограничениями и прочими настройками.
Однако при этом мы не сможем настроить QoS в его исконном значении: выделить более важные потоки перед менее важными. Дело в том, что каждая простая очередь - сама по себе. Ключ priority работает лишь в дереве, когда все очереди растут из одного корня и относятся друг к другу с большим или меньшим почтением.
Второй причиной использовать "дерево" является быстродействие. В дереве все очереди обрабатываются одновременно, тогда как "простые очереди" обрабатываются последовательно, подобно правилам в таблицах Mangle, Filter или NAT. Правда почувствовать это можно лишь в крупных сетях с тысячами компьютеров и сотнями правил.
Источники:
Руководства:Очереди - PCQ
Руководства:Очереди - Взрывной режим прохождения трафика (Burst)
Queues - PCQ Examples
Начну с того, что PCQ - не совсем очередь. Это скорее некое устройство, состоящее из PCC, FIFO (собственно, очереди) и Token Bucket (ограничителя потока).
Судите сами:
Алгоритм работы PCQ очень прост: сперва он использует выбранные классификаторы, чтобы отличить один подпоток от другого, затем применяет персональные значения размера FIFO-очереди и ограничения для каждого подпотока, после чего группирует все подпотоки вместе и применяет общие значения размера FIFO-очереди и ограничения.
Параметры PCQ:
pcq-classifier (dst-address | dst-port | src-address | src-port; default: ""): выбор идентификаторов подпотока
pcq-rate (число): максимально доступная скорость передачи данных каждого подпотока
pcq-limit (число): размер очереди для одного подпотока (в килобайтах)
pcq-total-limit (число): размер очереди для общей FIFO-очереди (в килобайтах)
Т.е. сначала мы при помощи pcq-classifier разделяем поток на струи по признаку адреса/порта отправителя или получателя. Подобно PCC!
Затем полученные струи выстраиваются в обычную очередь FIFO (используются такие настройки, как pcq-limit и pcq-total-limit).
При этом к ним применяются ограничения, ровно такие же, как в HTB (pcq-rate вместо limit-at) и даже возможны всплески (ключи burst-limit, burst-time, burst-threshold)!
Очевидно, что это могучий инструмент. И если его грамотно использовать, то можно решить многие из повседневно встречающихся задач, не прибегая к дереву очередей.
Моя задача проста: поровну распределить трафик между пользователями локальной сети (точно как в PCQ Examples).
Насколько я знаю, единственный способ направить поток пакетов в очередь - это выделить его в таблице Mangle любой цепочки. Что-бы снизить нагрузку на маршрутизатор, я сначала выделю соединения, а затем уже на основе этих меток выделю пакеты:
Код: Выделить всё
add action=mark-connection chain=prerouting in-interface=Bridge_Local new-connection-mark=client_upload_conn
add action=mark-packet chain=prerouting connection-mark=client_upload_conn new-packet-mark=client_upload
add action=mark-connection chain=prerouting in-interface=ether2-Inet new-connection-mark=client_download_conn
add action=mark-packet chain=prerouting connection-mark=client_download_conn new-packet-mark=client_download
Затем я чуть подправил очереди, заботливо созданные разработчиками RouterOS:
Код: Выделить всё
/queue type>
set 5 pcq-burst-rate=2M pcq-burst-threshold=512k pcq-burst-time=1m pcq-limit=500 pcq-rate=1M pcq-total-limit=20000
set 6 pcq-burst-rate=2M pcq-burst-threshold=512k pcq-burst-time=1m pcq-limit=500 pcq-rate=1M pcq-total-limit=20000В полном виде они теперь выглядят так:
/queue type print
......
......
......
5 * name="pcq-upload-default" kind=pcq pcq-rate=1M pcq-limit=500 pcq-classifier=src-address pcq-total-limit=20000 pcq-burst-rate=2M
pcq-burst-threshold=512k pcq-burst-time=1m pcq-src-address-mask=32 pcq-dst-address-mask=32 pcq-src-address6-mask=128
pcq-dst-address6-mask=128
6 * name="pcq-download-default" kind=pcq pcq-rate=1M pcq-limit=500 pcq-classifier=dst-address pcq-total-limit=20000 pcq-burst-rate=2M
pcq-burst-threshold=512k pcq-burst-time=1m pcq-src-address-mask=32 pcq-dst-address-mask=32 pcq-src-address6-mask=128
pcq-dst-address6-mask=128
......
......
......
Ну и третьим шагом я создаю простую очередь:
Код: Выделить всё
/queue simple
add burst-limit=3M/3M burst-threshold=512k/512k burst-time=20s/20s limit-at=2M/2M max-limit=2M/2M name=queue1 packet-marks=client_download,client_upload queue=pcq-upload-default/pcq-download-default target=192.168.10.0/24 time=8h-17h,mon,tue,wed,thu,friС помощью target вы указываете направление, относительно которого будет считаться исходящий и входящий трафик!
В данном случае я взял за основу направление в локальную сеть: оно считается входящим (download).
И ещё раз хочу обратить внимание вот на что.
Даже в этом простом примере у нас есть вложенность ограничений и всплесков. Мы можем настроить ограничения для потоков PCQ (pcq-rate) и для всей очереди (limit-at, max-limit).
То же самое касается "вёдер", в которых накапливаются марки для всплесков: pcq-burst-rate, pcq-burst-threshold, pcq-burst-time для PCQ и burst-limit, burst-threshold, burst-time для очереди в целом.
Представляете, какую невероятную гибкость это нам даёт?
К примеру, мы можем на первом шаге выделить трафик по виду (HTTP, ICMP, P2P) и отправить в разные очереди с разными ограничениями и прочими настройками.
Однако при этом мы не сможем настроить QoS в его исконном значении: выделить более важные потоки перед менее важными. Дело в том, что каждая простая очередь - сама по себе. Ключ priority работает лишь в дереве, когда все очереди растут из одного корня и относятся друг к другу с большим или меньшим почтением.
Второй причиной использовать "дерево" является быстродействие. В дереве все очереди обрабатываются одновременно, тогда как "простые очереди" обрабатываются последовательно, подобно правилам в таблицах Mangle, Filter или NAT. Правда почувствовать это можно лишь в крупных сетях с тысячами компьютеров и сотнями правил.
Последний раз редактировалось Barvinok 25 фев 2014, 10:41, всего редактировалось 21 раз.
-
Barvinok
- Сообщения: 104
- Зарегистрирован: 28 фев 2012, 23:21
Дерево очередей
Источники: Руководства:Очередь (Queue)
Mikrotik-Qos Приоритезация по типу трафика и деление скорости
Возьму простой случай: локальная сеть небольшого предприятия.
30 рабочих мест в локалке, пять удалённых филиалов по L2TP, канал 6 МБита.
Откровенно говоря, для работы шести мегабит должно хватать.
На деле канал сразу забивается каким-то HTTP-потоком на один компьютер.
И есть у меня сильное подозрение, что это всё таки котэ...
Мне нужно распределить весь поток по виду трафика, а полученные струи равномерно распределить между всеми компьютерами.
Микротик умеет различать 8 уровней важности очередей (priority=1...8).
Вышеозначенное руководство предлагает делать так:
Пойдём по порядку.
1. Флагманские сервисы (Priority=1): DNS, SSH, ICMP, Telnet, HTTP request.
Я позволил себе вычеркнуть HTTPS: четверть сайтов в интернете использует его вместо HTTP в том числе и для закачек. Не вижу причин придавать ему такую важность.
При всей своей важности, в обычном случае этого трафика не может быть много (если это не затопление). Полосы в 32 kbps на каждый компьютер будет достаточно.
2. Пользовательские запросы. В статье это различные он-лайн игры. Но статься написана для провайдера, раздающего интернет по квартирам. Я же говорю об офисе, где игры не в почёте.
Этот трафик я буду просто блокировать.
3. Коммуникационные сервисы (Priority=3): различная видео и голосовая связь (VoIP, Skype), а так же шифрованные туннели (VPN, HTTPS).
Объём здесь может быть изрядным, но давать больше 0,5 МБита на компьютер можно только если канал свободен:
limit-at=512kbps
max-limit=2Mbps
4. Сервисы закачек (Priority=5): HTTP download, FTP, SFTP. Они похожа на P2P тем, что даже один пользователь может с лёгкостью забить весь канал. Но есть и одно важное отличие: для пользователя они служат показателем отзывчивости. Скачивая файл в сети P2P вы даже не заметите, что скорость постоянно скачет, а иногда и вовсе замирает на несколько минут.
А вот нажав на ссылку вы хотите что бы желаемая страница открывалась мгновенно. Здесь нам и пригодится ведро.
Пусть файлы размером до 1 МБайта скачиваются на максимальной скорости, а всё, что больше - уже на малой, потихоньку:
limit-at=1Mbps
max-limit=2Mbps
burst-limit=2Mbps
burst-threshold=512kbps
burst-time=16s
5. Ну и, наконец, сервисы P2P (Priority=8). Тут всплески бессмысленны, а канал им нужно выдавать лишь при простое.
limit-at=0Mbps
max-limit=2Mbps
Начнём, помолясь...
Шаг 1. Выделение потоков.
Теперь пояснения почему так и именно в этой последовательности.
Сначала разберусь с обращениями к самому Микротику. Я снаружи практически всё перекрыл фильтрами, поэтому могу уверенно сказать, что никакого мусорного трафика в цепочке Input у меня нет. Снаружи разрешены Winbox, SSH (на нестандартном порту), L2TP-подключения и ICMP для служебных надобностей.
Для локальной сети мой маршрутизатор является сервером времени и доменных имён (DNS и NTP по UDP). Фильтрами от локалки я не отгораживался, хотя в некоторых случаях это имеет смысл.
Это важные службы, требующие хорошей отзывчивости.Помечаем все входящие соединения на входе и маркируем их пакеты на выходе меткой "Prio_3".
Соединения я помечаю в Input, а пакеты в Output. Т.е. я помечаю именно ответы на запросы.
Так же обратите внимание на passthrough=no. Эти пакеты не пойдут дальше по цепочке правил!
Теперь разберёмся с исходящими пакетами, которые не попали под предыдущее правило. Очевидно, что это пакеты, производимые самим маршрутизатором без внешнего побуждения.Как я уже сказал, маршрутизатор является сервером времени и имён. Поэтому время от времени обращается по своим надобностям к различным серверам в интернете. Как правило, это UDP 53 и 123. Но таблице общеизвестных портов, это могут быть и TCP-порты. Так же маршрутизатор может сообщаться по ICMP, а в некоторых случаях и по другим протоколам. Поэтому я, не указывая явно протокол, снова выделяю ВСЕ исходящие соединения и следующим правилом помечаю их пакеты меткой "Proi_1". Да, маршрутизатор не будет генерить всякую ерунду. Это самые важные сообщения и именно от них зависит быстродействие всех прочих служб сети в целом.
Теперь займёмся потоками, проходящими сквозь маршрутизатор из локальной сети в интернет и обратно.
В первую голову выберем HTTP. Почему я начинаю именно с него?
Да по простой причине: это 90% всего трафика. Я не хочу что бы вся эта масса пакетов последовательно проходила всю длинную цепочку правил в Mangle!Первыми двумя правилами я выделяю поток HTTP-download (загрузки файлов по HTTP). Отличительным признаком этих пакетов является connection-bytes=500000-0 (подробности здесь).
Те пакеты, что не попали под это правило идут дальше и вылавливаются по признаку лишь порта назначения. Соответственно, и обращение с этими двумя потоками будет разным.
Опять же, благодаря passthrough=no эти пакеты не побегут дальше по цепочке правил.
Теперь то, ради чего я всё это затевал: SIP!Ему я даю метку "Prio_2".
RDP:
FTP я выделяю двумя способами:Что любопытно: по признаку connection-type трафика помечается в разы больше, чем по порту назначения. А вот в случае с SIP-протоколом этот способ вообще не сработал... 
В завершение помечаем трафик не учтённый предыдущими правилами:
Да, есть ещё восьмой приоритет. Его я приберёг для P2P. Но поскольку в данном случае сказка сказывается об офисном маршрутизаторе, с P2P я поступил просто:
В противном случае я поставил бы его даже перед HTTP!
Источники: Руководства:Очередь (Queue)
Mikrotik-Qos Приоритезация по типу трафика и деление скорости
Возьму простой случай: локальная сеть небольшого предприятия.
30 рабочих мест в локалке, пять удалённых филиалов по L2TP, канал 6 МБита.
Откровенно говоря, для работы шести мегабит должно хватать.
На деле канал сразу забивается каким-то HTTP-потоком на один компьютер.
И есть у меня сильное подозрение, что это всё таки котэ...
Мне нужно распределить весь поток по виду трафика, а полученные струи равномерно распределить между всеми компьютерами.
Микротик умеет различать 8 уровней важности очередей (priority=1...8).
Вышеозначенное руководство предлагает делать так:
- Флагманские сервисы (Priority=1)
- Пользовательские запросы (Priority=3)
- Коммуникационные сервисы (Priority=5)
- Сервисы закачек (Priority=7)
- Сервисы P2P (Priority=8)
Пойдём по порядку.
1. Флагманские сервисы (Priority=1): DNS, SSH, ICMP, Telnet, HTTP request.
Я позволил себе вычеркнуть HTTPS: четверть сайтов в интернете использует его вместо HTTP в том числе и для закачек. Не вижу причин придавать ему такую важность.
При всей своей важности, в обычном случае этого трафика не может быть много (если это не затопление). Полосы в 32 kbps на каждый компьютер будет достаточно.
2. Пользовательские запросы. В статье это различные он-лайн игры. Но статься написана для провайдера, раздающего интернет по квартирам. Я же говорю об офисе, где игры не в почёте.
Этот трафик я буду просто блокировать.
3. Коммуникационные сервисы (Priority=3): различная видео и голосовая связь (VoIP, Skype), а так же шифрованные туннели (VPN, HTTPS).
Объём здесь может быть изрядным, но давать больше 0,5 МБита на компьютер можно только если канал свободен:
limit-at=512kbps
max-limit=2Mbps
4. Сервисы закачек (Priority=5): HTTP download, FTP, SFTP. Они похожа на P2P тем, что даже один пользователь может с лёгкостью забить весь канал. Но есть и одно важное отличие: для пользователя они служат показателем отзывчивости. Скачивая файл в сети P2P вы даже не заметите, что скорость постоянно скачет, а иногда и вовсе замирает на несколько минут.
А вот нажав на ссылку вы хотите что бы желаемая страница открывалась мгновенно. Здесь нам и пригодится ведро.
Пусть файлы размером до 1 МБайта скачиваются на максимальной скорости, а всё, что больше - уже на малой, потихоньку:
limit-at=1Mbps
max-limit=2Mbps
burst-limit=2Mbps
burst-threshold=512kbps
burst-time=16s
5. Ну и, наконец, сервисы P2P (Priority=8). Тут всплески бессмысленны, а канал им нужно выдавать лишь при простое.
limit-at=0Mbps
max-limit=2Mbps
Начнём, помолясь...
Шаг 1. Выделение потоков.
Код: Выделить всё
0 ;;; Mark input ROS connection
chain=input action=mark-connection new-connection-mark=ROS_conn passthrough=yes
1 ;;; Mark response ROS packets to Prio_3
chain=output action=mark-packet new-packet-mark=Prio_3 passthrough=no connection-mark=ROS_conn
2 ;;; Mark output connection
chain=output action=mark-connection new-connection-mark=out_conn passthrough=yes
3 ;;; Mark output packets to Prio_1
chain=output action=mark-packet new-packet-mark=Prio_1 passthrough=no connection-mark=out_conn
4 ;;; Mark HTTP downloads connection
chain=forward action=mark-connection new-connection-mark=http-dl_conn passthrough=yes protocol=tcp dst-port=80,443 connection-bytes=500000-0
5 ;;; Mark HTTP downloads packets to Prio_6
chain=forward action=mark-packet new-packet-mark=Prio_6 passthrough=no connection-mark=http-dl_conn
6 ;;; Mark HTTP connection
chain=forward action=mark-connection new-connection-mark=http_conn passthrough=yes protocol=tcp dst-port=80,443
7 ;;; Mark HTTP packets to Prio_5
chain=forward action=mark-packet new-packet-mark=Prio_5 passthrough=no connection-mark=http_conn
8 ;;; Mark SIP connection
chain=forward action=mark-connection new-connection-mark=SIP_conn passthrough=yes dst-address=81.88.86.11
9 ;;; Mark SIP packets to Prio_2
chain=forward action=mark-packet new-packet-mark=Prio_2 passthrough=no connection-mark=SIP_conn
10 ;;; Mark RDP connection
chain=forward action=mark-connection new-connection-mark=rdp_conn passthrough=yes protocol=tcp dst-port=3389
11 ;;; Mark RDP packets to Prio_4
chain=forward action=mark-packet new-packet-mark=Prio_4 passthrough=no connection-mark=rdp_conn
12 ;;; Mark FTP connection
chain=forward action=mark-connection new-connection-mark=ftp_conn passthrough=yes protocol=tcp dst-port=20-22
13 ;;; Mark FTP connection
chain=forward action=mark-connection new-connection-mark=ftp_conn passthrough=yes protocol=tcp connection-type=ftp
14 ;;; Mark FTP packets to Prio_6
chain=forward action=mark-packet new-packet-mark=Prio_6 passthrough=no connection-mark=ftp_conn
15 ;;; Mark all other connection
chain=forward action=mark-connection new-connection-mark=other_conn passthrough=yes
16 ;;; Mark all other packets to Prio_7
chain=forward action=mark-packet new-packet-mark=Prio_7 passthrough=yes connection-mark=other_conn Теперь пояснения почему так и именно в этой последовательности.
Сначала разберусь с обращениями к самому Микротику. Я снаружи практически всё перекрыл фильтрами, поэтому могу уверенно сказать, что никакого мусорного трафика в цепочке Input у меня нет. Снаружи разрешены Winbox, SSH (на нестандартном порту), L2TP-подключения и ICMP для служебных надобностей.
Для локальной сети мой маршрутизатор является сервером времени и доменных имён (DNS и NTP по UDP). Фильтрами от локалки я не отгораживался, хотя в некоторых случаях это имеет смысл.
Это важные службы, требующие хорошей отзывчивости.
Код: Выделить всё
0 ;;; Mark input ROS connection
chain=input action=mark-connection new-connection-mark=ROS_conn passthrough=yes
1 ;;; Mark response ROS packets to Prio_3
chain=output action=mark-packet new-packet-mark=Prio_3 passthrough=no connection-mark=ROS_conn
Соединения я помечаю в Input, а пакеты в Output. Т.е. я помечаю именно ответы на запросы.
Так же обратите внимание на passthrough=no. Эти пакеты не пойдут дальше по цепочке правил!
Теперь разберёмся с исходящими пакетами, которые не попали под предыдущее правило. Очевидно, что это пакеты, производимые самим маршрутизатором без внешнего побуждения.
Код: Выделить всё
2 ;;; Mark output connection
chain=output action=mark-connection new-connection-mark=out_conn passthrough=yes
3 ;;; Mark output packets to Prio_1
chain=output action=mark-packet new-packet-mark=Prio_1 passthrough=no connection-mark=out_conn
Теперь займёмся потоками, проходящими сквозь маршрутизатор из локальной сети в интернет и обратно.
В первую голову выберем HTTP. Почему я начинаю именно с него?
Да по простой причине: это 90% всего трафика. Я не хочу что бы вся эта масса пакетов последовательно проходила всю длинную цепочку правил в Mangle!
Код: Выделить всё
4 ;;; Mark HTTP downloads connection
chain=forward action=mark-connection new-connection-mark=http-dl_conn passthrough=yes protocol=tcp dst-port=80,443 connection-bytes=500000-0
5 ;;; Mark HTTP downloads packets to Prio_6
chain=forward action=mark-packet new-packet-mark=Prio_6 passthrough=no connection-mark=http-dl_conn
6 ;;; Mark HTTP connection
chain=forward action=mark-connection new-connection-mark=http_conn passthrough=yes protocol=tcp dst-port=80,443
7 ;;; Mark HTTP packets to Prio_5
chain=forward action=mark-packet new-packet-mark=Prio_5 passthrough=no connection-mark=http_conn
Те пакеты, что не попали под это правило идут дальше и вылавливаются по признаку лишь порта назначения. Соответственно, и обращение с этими двумя потоками будет разным.
Опять же, благодаря passthrough=no эти пакеты не побегут дальше по цепочке правил.
Теперь то, ради чего я всё это затевал: SIP!
Код: Выделить всё
8 ;;; Mark SIP connection
chain=forward action=mark-connection new-connection-mark=SIP_conn passthrough=yes dst-address=81.88.86.11
9 ;;; Mark SIP packets to Prio_2
chain=forward action=mark-packet new-packet-mark=Prio_2 passthrough=no connection-mark=SIP_conn
RDP:
Без комментариев.10 ;;; Mark RDP connection
chain=forward action=mark-connection new-connection-mark=rdp_conn passthrough=yes protocol=tcp dst-port=3389
11 ;;; Mark RDP packets to Prio_4
chain=forward action=mark-packet new-packet-mark=Prio_4 passthrough=no connection-mark=rdp_conn
FTP я выделяю двумя способами:
Код: Выделить всё
12 ;;; Mark FTP connection
chain=forward action=mark-connection new-connection-mark=ftp_conn passthrough=yes protocol=tcp dst-port=20-22
13 ;;; Mark FTP connection
chain=forward action=mark-connection new-connection-mark=ftp_conn passthrough=yes protocol=tcp connection-type=ftp
14 ;;; Mark FTP packets to Prio_6
chain=forward action=mark-packet new-packet-mark=Prio_6 passthrough=no connection-mark=ftp_conn
В завершение помечаем трафик не учтённый предыдущими правилами:
Надо сказать, что на боевом маршрутизаторе таких соединений я наблюдаю совсем не много (можно сосчитать по пальцам на одной руке). Значит, всё правильно сделал15 ;;; Mark all other connection
chain=forward action=mark-connection new-connection-mark=other_conn passthrough=yes
16 ;;; Mark all other packets to Prio_7
chain=forward action=mark-packet new-packet-mark=Prio_7 passthrough=yes connection-mark=other_conn
Да, есть ещё восьмой приоритет. Его я приберёг для P2P. Но поскольку в данном случае сказка сказывается об офисном маршрутизаторе, с P2P я поступил просто:
Код: Выделить всё
/ip firewall filter add action=drop chain=forward comment="Drop P2P" p2p=all-p2pВ противном случае я поставил бы его даже перед HTTP!
Последний раз редактировалось Barvinok 31 июл 2014, 23:55, всего редактировалось 18 раз.
-
Barvinok
- Сообщения: 104
- Зарегистрирован: 28 фев 2012, 23:21
Шаг 2. Построение дерева.
Рассказываю.
Есть два места, где мы можем расположить наши очереди и, собственно, настроить ограничения:
В отличие от simple queue, где мы можем сделать, к примеру, так:Т.е. мы указываем направление (target) приняв его за download и от него танцуем.
Но с HTB у нас получается прелюбопытнейшая штука. Мы можем разместить его на интерфейсе и он будет работать с исходящим через этот интерфейс трафиком. Ведь только исходящий трафик помечен у нас в Mangle, верно?
Значит мы имеем два случая:
1. Делаем два дерева. Первое размещаем на интерфейсе, который смотрит в интернет, второе - на том, который смотрит в локальную сеть;
2. Если канал у нас симметричный, то и трафик у нас будет нарезаться одинаков. Тогда можно сделать изящнее. В Mangle отдельно размечаем входящие и исходящие потоки и обходимся одним деревом в Global .
Указав корнем очереди Global мы размещаем её в самой IP-Tables. А она у нас однонаправленная! Т.е. для IP-Tables совсем не важно, через сколько интерфейсов втекает и вытекает трафик. Для неё поток всегда один: из Prerouting через Forward в Postrouting. Либо он же может быть направлен в Input.
Я имею симметричный канал шириной в 6 МБит. Те метки, что я укажу в цепочке Input ограничат поток к службам RouterOS. Я такого не делал: в Input я помечал только соединения, а пакеты этих соединений уже в Output. Так что моё дерево работает лишь в цепочке Postrouting причём для абсолютно всех соединений: идут ли они из локальной сети в интернет или наоборот. Для HTB это не важно. Он работает с тем, что было отмечено в Mangle.
Ещё у меня есть резервный ADSL. Он не симметричный, как вы понимаете: входящий 6 МБ / исходящий 1МБ.
Так что в случае переключения, на входящий поток у меня по прежнему будет работать вышеозначенное дерево в Global, а на исходящий интерфейс придётся повесить второе дерево:Недостатком такого решения является то, что исходящий поток будет последовательно проходить через два дерева: сначала в Global, а потом на интерфейсе PPPoE. Но это же резервный канал. Может он вообще никогда не задействуется... Но по хорошему в Global надо вешать совсем уж универсальные правила, а на каждый интерфейс своё собственное дерево, учитывающее его особенности. Ну, в целом, я думаю, концепция ясна.
Перейдём к заключительной фазе.
Потоки по виду трафика мы разделили. По важности в дереве развесили.
Но ведь пользователей то у нас много! Надо же теперь каждый вид трафика справедливо распределить между ними!
Т.е. согласно адресов источников.
Шаг 3. Равномерное распределение между пользователями.
Для равномерного распределения используем виды очередей (queue type).
По умолчанию вид очереди ставится queue=default-small.
Как видно, это обычный First In, First Out — «первым пришёл — первым ушёл» длиной в 10 пакетов. Это нормально для одного устройства (самого маршрутизатора, к примеру), но для разделения между пользователями не подходит совершенно.
У меня в сети два десятка SIP-телефонов. Никаких всплесков там быть не может. Нужно чёткое, равномерное распределение трафика между ними. Идеально с этим справится очередь SFQ. В дефолтных правилах это либо wireless-default либо hotspot-default (они абсолютно одинаково настроены).
Для совсем уж маловажного потокового трафика типа P2P я использую очередь RED, которая может и отбросить десяток-другой пакетов без лишних церемоний (queue=synchronous-default).
Для HTTP-трафика нужно предусмотреть всплески. Значит используем PCQ (слегка видоизменённый pcq-upload-default). pcq-classifier=src-port по той причине, что дерево расположено после таблицы SNAT. А значит адрес источника у всех пакетов = внешний адрес самого роутера.
Тут я вижу некоторое слабость. К примеру, один компьютер имея несколько десятков подключений захватывает весь доступный канал. Но как с этим справиться простым способом - не представляю.
Но обычно для нас более важен входящий трафик - и тут никаких трудностей нет: pcq-classifier=dst-address
Я не вижу задач, которые нельзя было решить в эти три шага.
Но тем не менее замечу, что после HTB Global мы можем ещё раз порезать трафик в simple queue, а потом ещё раз в HTB на интерфейсах. Страшно представить, что таким образом можно накрутить...
Надо сказать, что правил у нас получилось немного (в сравнении с решением Inlariona), но они "наукоёмкие". Т.е. мы задействовали большинство возможностей, предоставляемых RouterOS. С одной стороны это предъявляет некоторые требования к администратору. Но с другой - знать то их всё равно надо. А чем меньше правил - тем проще жить!
Код: Выделить всё
/queue tree> print
Flags: X - disabled, I - invalid
0 ;;; Root of global queue
name="Global_L1" parent=global packet-mark="" limit-at=0 queue=default-small priority=8 max-limit=6M burst-limit=0 burst-threshold=0 burst-time=0s
1 name="Global_L2" parent=Global_L1 packet-mark="" limit-at=3M queue=default-small priority=8 max-limit=5M burst-limit=0 burst-threshold=0 burst-time=0s
2 name="Global_P1" parent=Global_L1 packet-mark=Prio_1 limit-at=512k queue=default-small priority=1 max-limit=1M burst-limit=0 burst-threshold=0 burst-time=0s
3 name="Global_P2" parent=Global_L1 packet-mark=Prio_2 limit-at=2M queue=hotspot-default priority=2 max-limit=4M burst-limit=0 burst-threshold=0 burst-time=0s
4 name="Global_P3" parent=Global_L2 packet-mark=Prio_3 limit-at=1M queue=default-small priority=3 max-limit=5M burst-limit=0 burst-threshold=0 burst-time=0s
5 name="Global_P4" parent=Global_L2 packet-mark=Prio_4 limit-at=1M queue=pcq-upload-default priority=4 max-limit=3M burst-limit=6M burst-threshold=1M burst-time=20s
6 name="Global_P5" parent=Global_L2 packet-mark=Prio_5 limit-at=1M queue=pcq-upload-default priority=5 max-limit=5M burst-limit=6M burst-threshold=1M burst-time=20s
7 name="Global_P6" parent=Global_L2 packet-mark=Prio_6 limit-at=1M queue=pcq-upload-default priority=6 max-limit=3M burst-limit=6M burst-threshold=1M burst-time=20s
8 name="Global_P7" parent=Global_L2 packet-mark=Prio_7 limit-at=1M queue=default-small priority=7 max-limit=5M burst-limit=5M burst-threshold=1M burst-time=1m
9 name="Global_P8" parent=Global_L2 packet-mark=Prio_8 limit-at=512k queue=synchronous-default priority=8 max-limit=2M burst-limit=0 burst-threshold=0 burst-time=0s
Рассказываю.
Есть два места, где мы можем расположить наши очереди и, собственно, настроить ограничения:
- Global - в конце цепочек Input и Postrouting. Это раз!
- на интерфейсах (ether1, ether2.... etherN) - за пределами IPTables. Это два
Дерево очередей создаёт лишь однонаправленную очередь в одном [месте]!Manual:Queue писал(а):Queue tree creates only one directional queue in one of the HTBs.
В отличие от simple queue, где мы можем сделать, к примеру, так:
Код: Выделить всё
/queue simple
add burst-limit=10M/10M burst-threshold=4M/4M burst-time=1m/1m limit-at=4M/4M max-limit=8M/8M name=queue1 packet-marks=client_download,client_upload queue=pcq-upload-default/pcq-download-default target=\
192.168.10.0/24 time=8h-17h,mon,tue,wed,thu,fri
Но с HTB у нас получается прелюбопытнейшая штука. Мы можем разместить его на интерфейсе и он будет работать с исходящим через этот интерфейс трафиком. Ведь только исходящий трафик помечен у нас в Mangle, верно?
Значит мы имеем два случая:
1. Делаем два дерева. Первое размещаем на интерфейсе, который смотрит в интернет, второе - на том, который смотрит в локальную сеть;
2. Если канал у нас симметричный, то и трафик у нас будет нарезаться одинаков. Тогда можно сделать изящнее. В Mangle отдельно размечаем входящие и исходящие потоки и обходимся одним деревом в Global .
Указав корнем очереди Global мы размещаем её в самой IP-Tables. А она у нас однонаправленная! Т.е. для IP-Tables совсем не важно, через сколько интерфейсов втекает и вытекает трафик. Для неё поток всегда один: из Prerouting через Forward в Postrouting. Либо он же может быть направлен в Input.
Я имею симметричный канал шириной в 6 МБит. Те метки, что я укажу в цепочке Input ограничат поток к службам RouterOS. Я такого не делал: в Input я помечал только соединения, а пакеты этих соединений уже в Output. Так что моё дерево работает лишь в цепочке Postrouting причём для абсолютно всех соединений: идут ли они из локальной сети в интернет или наоборот. Для HTB это не важно. Он работает с тем, что было отмечено в Mangle.
Ещё у меня есть резервный ADSL. Он не симметричный, как вы понимаете: входящий 6 МБ / исходящий 1МБ.
Так что в случае переключения, на входящий поток у меня по прежнему будет работать вышеозначенное дерево в Global, а на исходящий интерфейс придётся повесить второе дерево:
Код: Выделить всё
10 I ;;; Root of MTS upload queue
name="Upload_L1" parent=MTS-PPPoE packet-mark="" limit-at=0 queue=default-small priority=8 max-limit=1M burst-limit=0 burst-threshold=0 burst-time=0s
11 I name="Upload_L2" parent=Upload_L1 packet-mark="" limit-at=512k queue=default-small priority=8 max-limit=1M burst-limit=0 burst-threshold=0 burst-time=0s
12 I name="Upload_P1" parent=Upload_L1 packet-mark=Prio_1 limit-at=128k queue=default-small priority=1 max-limit=1M burst-limit=0 burst-threshold=0 burst-time=0s
13 I name="Upload_P2" parent=Upload_L1 packet-mark=Prio_2 limit-at=512k queue=hotspot-default priority=2 max-limit=1M burst-limit=0 burst-threshold=0 burst-time=0s
14 I name="Upload_P3" parent=Upload_L2 packet-mark=Prio_3 limit-at=128k queue=default-small priority=3 max-limit=1M burst-limit=0 burst-threshold=0 burst-time=0s
15 I name="Upload_P4" parent=Upload_L2 packet-mark=Prio_4 limit-at=128k queue=default-small priority=4 max-limit=1M burst-limit=0 burst-threshold=0 burst-time=0s
16 I name="Upload_P5" parent=Upload_L2 packet-mark=Prio_5 limit-at=128k queue=default-small priority=5 max-limit=1M burst-limit=0 burst-threshold=0 burst-time=0s
17 I name="Upload_P6" parent=Upload_L2 packet-mark=Prio_6 limit-at=128k queue=default-small priority=6 max-limit=1M burst-limit=0 burst-threshold=0 burst-time=0s
18 I name="Upload_P7" parent=Upload_L2 packet-mark=Prio_7 limit-at=128k queue=default-small priority=7 max-limit=1M burst-limit=0 burst-threshold=0 burst-time=0s
19 I name="Upload_P8" parent=Upload_L2 packet-mark=Prio_8 limit-at=32k queue=synchronous-default priority=8 max-limit=128k burst-limit=0 burst-threshold=0 burst-time=0s
Перейдём к заключительной фазе.
Потоки по виду трафика мы разделили. По важности в дереве развесили.
Но ведь пользователей то у нас много! Надо же теперь каждый вид трафика справедливо распределить между ними!
Т.е. согласно адресов источников.
Шаг 3. Равномерное распределение между пользователями.
Для равномерного распределения используем виды очередей (queue type).
Код: Выделить всё
/queue type> print
Flags: * - default
0 * name="default" kind=pfifo pfifo-limit=50
1 * name="ethernet-default" kind=pfifo pfifo-limit=50
2 * name="wireless-default" kind=sfq sfq-perturb=5 sfq-allot=1514
3 * name="synchronous-default" kind=red red-limit=60 red-min-threshold=10 red-max-threshold=50 red-burst=20 red-avg-packet=1000
4 * name="hotspot-default" kind=sfq sfq-perturb=5 sfq-allot=1514
5 * name="pcq-upload-default" kind=pcq pcq-rate=1M pcq-limit=50 pcq-classifier=src-port pcq-total-limit=2000 pcq-burst-rate=4M pcq-burst-threshold=1M pcq-burst-time=1m pcq-src-address-mask=32
pcq-dst-address-mask=32 pcq-src-address6-mask=128 pcq-dst-address6-mask=128
6 * name="pcq-download-default" kind=pcq pcq-rate=1M pcq-limit=50 pcq-classifier=dst-address pcq-total-limit=2000 pcq-burst-rate=4M pcq-burst-threshold=1M pcq-burst-time=1m pcq-src-address-mask=32
pcq-dst-address-mask=32 pcq-src-address6-mask=128 pcq-dst-address6-mask=128
7 * name="only-hardware-queue" kind=none
8 * name="multi-queue-ethernet-default" kind=mq-pfifo mq-pfifo-limit=50
9 * name="default-small" kind=pfifo pfifo-limit=10
По умолчанию вид очереди ставится queue=default-small.
Как видно, это обычный First In, First Out — «первым пришёл — первым ушёл» длиной в 10 пакетов. Это нормально для одного устройства (самого маршрутизатора, к примеру), но для разделения между пользователями не подходит совершенно.
У меня в сети два десятка SIP-телефонов. Никаких всплесков там быть не может. Нужно чёткое, равномерное распределение трафика между ними. Идеально с этим справится очередь SFQ. В дефолтных правилах это либо wireless-default либо hotspot-default (они абсолютно одинаково настроены).
Для совсем уж маловажного потокового трафика типа P2P я использую очередь RED, которая может и отбросить десяток-другой пакетов без лишних церемоний (queue=synchronous-default).
Для HTTP-трафика нужно предусмотреть всплески. Значит используем PCQ (слегка видоизменённый pcq-upload-default). pcq-classifier=src-port по той причине, что дерево расположено после таблицы SNAT. А значит адрес источника у всех пакетов = внешний адрес самого роутера.
Тут я вижу некоторое слабость. К примеру, один компьютер имея несколько десятков подключений захватывает весь доступный канал. Но как с этим справиться простым способом - не представляю.
Но обычно для нас более важен входящий трафик - и тут никаких трудностей нет: pcq-classifier=dst-address
Я не вижу задач, которые нельзя было решить в эти три шага.
Но тем не менее замечу, что после HTB Global мы можем ещё раз порезать трафик в simple queue, а потом ещё раз в HTB на интерфейсах. Страшно представить, что таким образом можно накрутить...
Надо сказать, что правил у нас получилось немного (в сравнении с решением Inlariona), но они "наукоёмкие". Т.е. мы задействовали большинство возможностей, предоставляемых RouterOS. С одной стороны это предъявляет некоторые требования к администратору. Но с другой - знать то их всё равно надо. А чем меньше правил - тем проще жить!
Последний раз редактировалось Barvinok 01 авг 2014, 15:20, всего редактировалось 13 раз.
-
megazlodey
- Сообщения: 9
- Зарегистрирован: 25 авг 2013, 13:24
Я создал правило маркировки пакетов, где увидеть количество промарканых пакетов, как понять работает ли правило маркировки?
-
simpl3x

- Модератор
- Сообщения: 1532
- Зарегистрирован: 19 апр 2012, 14:03
megazlodey писал(а):Я создал правило маркировки пакетов, где увидеть количество промарканых пакетов, как понять работает ли правило маркировки?
у каждого правила маркировки справа есть счётчки (counter) - отображает количество случаев, когда сработало правило.
-
KVN
- Сообщения: 26
- Зарегистрирован: 19 янв 2012, 13:11
- Откуда: UA
Код: Выделить всё
add action=mark-connection chain=forward in-interface=Bridge_Local new-connection-mark=upload_conn
add action=mark-connection chain=forward in-interface=UTK_PPPoE new-connection-mark=download_conn
add action=mark-packet chain=forward connection-mark=upload_conn new-packet-mark=upload_pac
add action=mark-packet chain=forward connection-mark=download_conn new-packet-mark=download_pac
Привет всем! Mikrotik 5.24 на х86.
Маркирую трафик похожим способом:
add action=mark-connection chain=forward disabled=no dst-address-list=office-user in-interface=PPPoE-OGO new-connection-mark=user-ogo-connection-down passthrough=yes
add action=mark-packet chain=forward connection-mark=user-ogo-connection-down disabled=no new-packet-mark=user-ogo-packet-down passthrough=no
add action=mark-connection chain=forward disabled=no new-connection-mark=user-ogo-connection-up out-interface=PPPoE-OGO passthrough=yes src-address-list=office-user
add action=mark-packet chain=forward connection-mark=user-ogo-connection-up disabled=no new-packet-mark=user-ogo-packet-up passthrough=no
Но скорость в колонке Rate совсем не такая как в реальности (несколько сотен kbps).
Не подскажите где искать загвоздку???